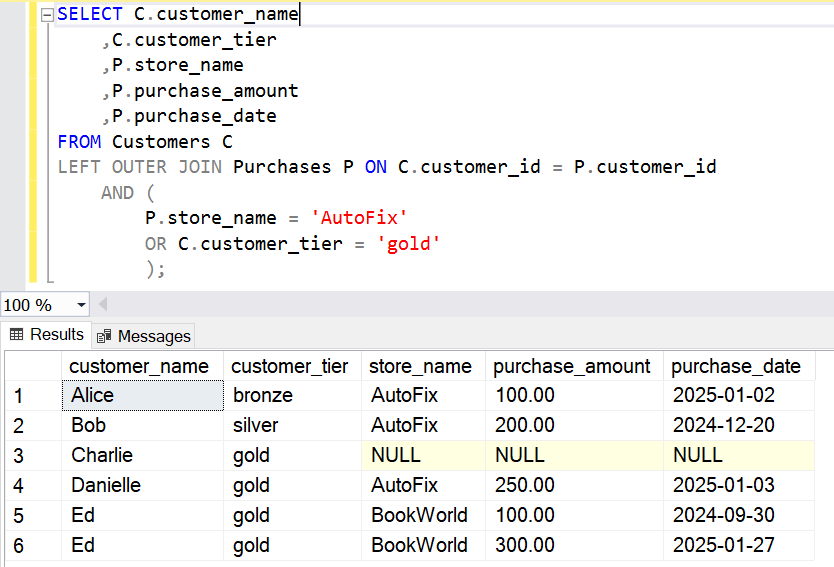
Of queries outer and inner, their correlated discourse guided by EXISTS to promptly identify that which is, not how many are.
Say you get a classic business data request: “Give me a list of customers who’ve purchased a book from the Cooking section of our bookshop.” In this case, we’re not concerned with aggregated sale amounts or how many books were bought. Instead, we simply want a list of customers who’ve made at least one purchase from the Cooking category—perhaps to alert them about an upcoming sale or a future in-store celebrity chef book-signing, or maybe we want information about a cohort of customers to act as source data for some further analysis.
Many other business questions fit such a pattern, such as “Which employees haven’t submitted a timesheet last month?” or “Which patients have appointments in this clinic next week and will need a reminder text?“. The key is that we don’t actually need details, we only want to identify the existence of data which satisfies a requirement. Fetching counts and other details is overkill for this purpose.
In this post I want to show you the power of SQL’s EXISTS keyword, which when combined with a type of query structure called a correlated subquery, enables you to answer specific “yes/no true/false” existence questions about your data in an intuitive, efficient and above all speedy way. It can bring significant reductions in query runtime with cleaner code.
Now EXISTS almost always comes along as a one-two punch with a correlated subquery. The “correlated” part absolutely took me a long time to get my head around way back when I was first learning SQL. Later in this post, I’ll share a simple way I learned to think about them which approaches the topic from a slightly different angle to most documentation (and which I wish someone could have told me about on day one!).
The EXISTS plus correlated subquery combo is a tool I genuinely want to make sure you have in your toolkit. It’s honestly that good, and can be a game-changer in the right situation. In fact, I naturally reach for this technique almost every day, yet it doesn’t seem to be as widely-known as it should be.
We’ll begin by looking at the EXISTS operator. It is essentially a test to determine whether a subquery returns any data, and returns a boolean result. If the subquery brings back no rows, it returns FALSE. No surprises there. However, and this is the awesome bit, as soon as the subquery brings back 1 row, it returns TRUE and STOPS THE SEARCH. That’s key. EXISTS doesn’t care if there is 1 “matching” row in the subquery or 1 million. EXISTS isn’t about counts; it’s just for answering the question “Is there any matching data?“. As soon as it sees 1 row, it has its answer and its work is done.
This “stop-at-the-first-match” behaviour is (as you can imagine) where the reductions in query runtime can come from. For example if you have a large sales table where many customers have hundreds or thousands of rows, and you only want to know who your active customers are, you can save a lot of reads by using EXISTS. There is no need to trawl through all of customer X’s sales if the request is merely “Has customer X purchased anything?“. As soon as EXISTS comes across the first match for that customer it stops the search, potentially saving a ton of unnecessary reads.
So if EXISTS is a “yes/no” check for the existence of data, what is a correlated subquery and how do they work together? Well I’m glad you asked! Let’s clarify what a non-correlated subquery is first. These are the subqueries you’ve most likely come across before, and may look something like the example below. The question is “What are the names of the customers on our VIP list?“.
SELECT CustomerName
FROM Customers
WHERE CustomerId IN (
SELECT CustomerId
FROM VIPCustomers
);In this case the subquery runs once and is totally independent of the rest of the query. The CustomerIds from the VIPCustomers table are returned to the “outer” or “parent” part of the query, which then filters the final output based on those values.
A correlated subquery on the other hand is NOT independent of the rest of the query. It will in fact reference columns from the “outer” query as it runs.
Confused yet? I sure was all those years ago! What’s all that about??
Let’s take a look at an abstract example of the SQL involved for a correlated subquery.
SELECT...
FROM OuterTable AS O
WHERE...(
SELECT...
FROM InnerTable AS I
WHERE I.TableID = O.TableID
);You may have already spotted the “I.TableID = O.TableID” fragment here, and indeed this is the correlation in action! It looks like we’re trying to match a column from inside the subquery with a column from the outer query. Believe it or not this actually works, and it can be mega-powerful.
Now in SQL documentation you will commonly see the correlated subquery pattern explained as “the subquery is running once for each row in the outer query“. When I was reading this for the first time, looking at the example query, then at that statement, then back at the query again, I could broadly see the connection the authour was trying to show, but I struggled to picture it in my mind’s eye. The code looked to me like there should be an INNER JOIN in there somewhere, but how could you join across isolated queries like this? How do we reach across these “scopes”? And the “subquery running once for each outer row” statement? That sounded like a description of a FOR loop in some other programming language – but how could you iterate over a collection in SQL like that? Here comes the nugget I was alluding to previously…
Indulge me and let’s step away from that explanation for a moment. Consider another angle. I imagine you’re familiar with the concept of a function call or a subroutine from another language (e.g. Python, C, Java), where you can pass in input parameter values. You leave a parent scope temporarily and pass an input value across a “boundary” into a different child code execution scope.
What if I proposed that you could think of a correlated subquery simply as a parameterised subroutine? Just another black box which takes input and can return output based on that input.
Imagine for a moment that everything inside the brackets in the example above as being a parameterised subroutine. The “I.TableID = O.TableID” section links or joins that black box to the outer query, and does the job of bringing input parameters (or in terms of our code analogy, arguments) into the correlated subquery / subroutine. Through that link, the outer query effectively executes the inner subroutine repeatedly, with the input parameters being a stream of values from the outer query.
Let’s roll with the analogy a little further. Conceptually we could think of the code in the brackets as a parameterised subroutine call such as:
isThereAnInnerTableMatch(O.TableID)
which, again purely conceptually, might make the whole query…
SELECT ...
FROM OuterTable AS O
WHERE isThereAnInnerTableMatch(O.TableID) = TRUE;We’ve certainly drifted well away from the original SQL query, but this was intentional. I wanted to reframe the logic of the correlated subquery in perhaps a more abstract pseudocode form. This mental model helped me when I struggled with SQL documentation explanations, and I hope it resonates with you too!
Source data
Time to get our hands dirty with some examples. These are the datasets we’ll be working with through this post.
dbo.Customers| customer_id | customer_name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | Danielle |
| 5 | Ed |
| book_id | book_name | book_category | book_price |
|---|---|---|---|
| 1 | The Art of French Cooking | Cooking | 29.99 |
| 2 | BBQ Mastery: Grilling Like a Pro | Cooking | 24.50 |
| 3 | Whispers of the Heart | Romance | 15.99 |
| 4 | The Duke’s Secret | Romance | 18.75 |
| 5 | Galactic Wars: The Rise of Andromeda | SciFi | 22.99 |
| 6 | Quantum Dreams | SciFi | 19.99 |
| 7 | Time Travelers of Mars | SciFi | 21.50 |
| 8 | The Fall of Rome | History | 27.99 |
| 9 | World War Chronicles | History | 30.00 |
| 10 | The Age of Pharaohs | History | 25.99 |
| sale_id | sale_date | sale_customer_id | sale_book_id |
|---|---|---|---|
| 1 | 2024-12-02 | 1 | 5 |
| 2 | 2024-04-19 | 2 | 3 |
| 3 | 2024-04-15 | 4 | 5 |
| 4 | 2024-03-20 | 5 | 8 |
| 5 | 2024-11-27 | 1 | 1 |
| 6 | 2024-09-16 | 5 | 6 |
| 7 | 2024-01-03 | 1 | 9 |
| 8 | 2024-07-04 | 2 | 9 |
| 9 | 2024-10-03 | 2 | 8 |
| 10 | 2024-03-19 | 5 | 9 |
| 11 | 2024-03-19 | 1 | 6 |
Let’s see how the data fits together.
SELECT c.customer_name
, s.sale_date
, b.book_name
, b.book_category
, b.book_price
FROM dbo.Customers AS c
INNER JOIN dbo.Sales AS s ON c.customer_id = s.sale_customer_id
INNER JOIN dbo.Books AS b ON s.sale_book_id = b.book_id
ORDER BY c.customer_name
, b.book_category
, b.book_name;
Real-world example breakdown
Armed with our mental model of a correlated subquery, let’s apply it alongside the EXISTS operator and take the whole solution for a test run with some examples.
Which customers have made a purchase?
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE EXISTS (
SELECT 1
FROM dbo.Sales AS s
WHERE s.sale_customer_id = c.customer_id
);
The result is a list of all customers who have made purchases. Note that Charlie isn’t in this list, because he hasn’t purchased anything yet.
Let’s apply our new EXISTS and correlated subquery knowledge, and deconstruct what’s going on here.
SELECT c.customer_name
FROM dbo.Customers AS c
- Straightforward, return the customer_name from the Customers table. Note that we have defined a c alias for the Customers table. This will have critical importance later in our correlated subquery.
WHERE EXISTS
- Here we add a WHERE filter to our query, and following that is the new keyword EXISTS. A subquery will come next. WHERE EXISTS is acting as an existence test, waiting for any data to come back from the subquery. As soon as the subquery returns any data, the WHERE EXISTS structure will stop that “execution” of the subquery.
(
SELECT 1
FROM dbo.Sales AS s
WHERE s.sale_customer_id = c.customer_id
)
- We’ve arrived at the correlated subquery itself. We are running a SELECT query against the Sales table, which we’ve aliased as s. We can tell this is a correlated subquery because inside it is a reference to a column which comes from outside, from the “parent” query;
c.customer_id. - Going back to what we’ve just learned, let’s think of the part in the brackets as being like a parameterised subroutine call, perhaps
doesCustomerHaveOrders(c.customer_id). Inside the subroutine, this SQL SELECT statement will (technically) return a 1 back to the parent query for every row from the Sales table where the sale_customer_id column value matches the c.customer_id being passed in. I put technically in parentheses there, because the EXISTS which is receiving the output of this subroutine will halt the subroutine’s execution for that specific c.customer_id as soon as that first 1 is received, immediately returning TRUE without looking for any further matches. - If you’re wondering “Why
SELECT 1?”, the answer is that EXISTS doesn’t care about the content of the data returned by the subquery, it only cares about the existence of any data coming back. We could have usedSELECT *orSELECT s.sale_customer_idif we wanted to. In the case of an EXISTS subquery however it is common practice to simply useSELECT 1to signal to any developer who may look at the code afterwards, that in this scenario we are only looking for a yes/no answer, and the data itself is irrelevant. Consider it a little friendly piece of self-documentation to make clear the intent.
Summarising in English:
For each customer in the Customers table, send that customer’s customer_id into a subquery. That subquery will look through the Sales table looking for a match on sale_customer_id. If there is a match, exit the subquery and return a true value to the parent query to signal that customer should be returned in the query output. If there isn’t a match, exit the subquery and return a false value to the parent query to signal that customer should NOT be returned in the query output.
And finally let’s look at the workflow with some of our sample data:
- The database engine fetches the first row from the Customers table – customer_id 1, customer_name ‘Alice‘.
- That customer_id value is passed into the correlated subquery, where it is referenced in that query’s WHERE clause. The subquery effectively becomes
SELECT 1 FROM dbo.Sales AS S WHERE s.sale_customer_id = 1. - The engine runs that parameterised “version” of the query (
WHERE s.sale_customer_id = 1). - If a match is found in the Sales table, and as soon as it is found, a 1 will be returned immediately to the EXISTS operator in the parent query. At this point the subquery can be terminated and a TRUE value passed back to the WHERE clause. The customer Alice will appear in the final output of the SELECT.
- If no match is found in the Sales table, the EXISTS operator will pass a FALSE value to the WHERE clause, and the customer Alice won’t appear in the final output of the SELECT.
- The database engine fetches the next row from the Customers table – customer_id 2, customer_name ‘Bob‘.
- That customer_id value is passed into the correlated subquery, and the subquery effectively becomes
SELECT 1 FROM dbo.Sales AS S WHERE s.sale_customer_id = 2.
Repeat for all rows in the Customers table.
Further examples
Let’s build our understanding with some other examples of this code structure in action.
We can flip the logic of EXISTS to NOT EXISTS.
Which customers have not made any purchases?
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE NOT EXISTS (
SELECT 1
FROM dbo.Sales AS S
WHERE s.sale_customer_id = c.customer_id
);
Sure enough, we see Charlie.
Looking at book sales instead:
Which books have not had any sales?
SELECT b.book_name
FROM dbo.Books AS b
WHERE NOT EXISTS (
SELECT 1
FROM dbo.Sales AS S
WHERE s.sale_book_id = b.book_id
);
We can make the queries in the parent query or the subquery as complex as we like. As long as the subquery returns a 1 for each row which matches our requirements, our EXISTS will work.
Also you aren’t just limited to 1 EXISTS in a query. You can chain multiple clauses to dramatically focus your search.
Who bought the book “The Fall of Rome”, and has never bought a romance book?
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE EXISTS (
SELECT 1
FROM dbo.Sales AS s_for
INNER JOIN dbo.Books AS b ON s_for.sale_book_id = b.book_id
WHERE s_for.sale_customer_id = c.customer_id
AND b.book_name = 'The Fall of Rome'
)
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales AS s_romance
INNER JOIN dbo.Books AS b ON s_romance.sale_book_id = b.book_id
WHERE s_romance.sale_customer_id = c.customer_id
AND b.book_category = 'Romance'
);
Indeed you can go very fine-grained with your EXISTS logic.
Who has only ever bought SciFi books worth more than £22?
SELECT c.customer_name
FROM dbo.Customers c
WHERE
/* Make sure the customer has purchased at least 1 book */
EXISTS (
SELECT 1
FROM dbo.Sales s
WHERE s.sale_customer_id = c.customer_id
)
/* Make sure the customer has NOT purchased any non-SciFi books */
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales s_non_scifi
INNER JOIN dbo.Books b_non_scifi ON s_non_scifi.sale_book_id = b_non_scifi.book_id
WHERE s_non_scifi.sale_customer_id = c.customer_id
AND b_non_scifi.book_category != 'SciFi'
)
/* Make sure the customer has NOT purchased any SciFi books which cost < £22 */
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales s_cheap_scifi
INNER JOIN dbo.Books b_cheap_scifi ON s_cheap_scifi.sale_book_id = b_cheap_scifi.book_id
WHERE s_cheap_scifi.sale_customer_id = c.customer_id
AND b_cheap_scifi.book_category = 'SciFi'
AND b_cheap_scifi.book_price <= 22
);
We can “nest” EXISTS clauses, passing correlated subquery “parameters” into deeper scopes.
Who purchased a history book which a different customer has purchased?
SELECT c.customer_name
FROM dbo.Customers c
WHERE EXISTS (
/* Has this customer purchased a history book? */
SELECT 1
FROM dbo.Sales s_hist1
INNER JOIN dbo.Books b_hist1 ON s_hist1.sale_book_id = b_hist1.book_id
WHERE s_hist1.sale_customer_id = c.customer_id
AND b_hist1.book_category = 'History'
AND EXISTS (
/* Has a different customer to the one we are looking at purchased the same book? */
SELECT 1
FROM dbo.Sales s_hist2
WHERE s_hist2.sale_book_id = s_hist1.sale_book_id
AND s_hist2.sale_customer_id != s_hist1.sale_customer_id
)
);
Performance considerations
As demonstrated, the EXISTS/correlated subquery combo can result in reduced runtimes owing to the way it stops looking as soon as the existence of 1 matching row has been identified. For the right datasets this short-circuit behaviour can be a real winner, and the wins tend to get better the larger the dataset is.
For maximum performance, ensure that the column(s) inside the correlated subquery you’re checking against values from the parent query are indexed. In the first example query above…
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE EXISTS (
SELECT 1
FROM dbo.Sales AS s
WHERE s.sale_customer_id = c.customer_id
);
… an index on the s.sale_customer_id column is more or less essential. Such an index will give the database engine the shortest possible path to finding a matching sale for the customer, because it will have a neat and sorted list of all sale_customer_id values ready to use for quick lookups. If the database engine doesn’t have a useful index to make use of with this query, it may resort to reading through the entire Sales table looking for matches. You may get lucky and the engine could find the right sale_customer_id early in the search, but it also may only find it only at the end of the process of reading through every single sale. And without an index the engine will have to read through the entire Sales table before it can say for certain a customer hasn’t made any purchases. An index will give your EXISTS shortcut a further shortcut!
Questions?
Is EXISTS always going to be a faster option than using a COUNT(*) or a JOIN?
As with just about every data question, the classic answer is “it depends”. For the very specific question of the pure existence of matching data, EXISTS is usually going to be your best bet because of the “short-circuit” behaviour. COUNTs and JOINs are designed to find every match, whereas EXISTS only needs to see 1, making it the optimal solution for these queries. Why look for each and every match when you’ve found one and have your existence answer already?
A possible scenario where the performance differences would be negligible is if, taking the example queries above, you had an index on the sales_customer_id column and you were 100% CERTAIN that there could only ever be 1 sale per customer. EXISTS would still stop after the 1 match, and both COUNT and JOIN would only see 1 match. Therefore the amount of rows read in each case, and subsequently the processing workloads would essentially be the same. Even then, I’d argue EXISTS would still be preferable because of the clarity of intent you get with that structure. Anyone reading the code in future (including you!) would clearly see that the code is specifically checking only for existence, and counts are not the goal.
If, however, you are looking for cases where there is more than 1 matching row, COUNT(*) is your best option!
In any case, couldn’t you still answer the question of “does matching data exist” using COUNT(*) / GROUP BY or INNER / OUTER JOINs?
Absolutely! Taking the example data above, you could write queries like…
SELECT c.customer_name
FROM dbo.Customers AS c
INNER JOIN dbo.Sales AS s ON c.customer_id = s.sale_customer_id
GROUP BY c.customer_name
HAVING COUNT(*) >= 1;
SELECT DISTINCT c.customer_name
FROM dbo.Customers AS c
INNER JOIN dbo.Sales AS s ON c.customer_id = s.sale_customer_id;
SELECT DISTINCT c.customer_name
FROM dbo.Customers AS c
LEFT OUTER JOIN dbo.Sales AS s ON c.customer_id = s.sale_customer_id
WHERE s.sale_customer_id IS NOT NULL;
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE c.customer_id IN (
SELECT s.sale_customer_id
FROM dbo.Sales AS s
);
Looking at performance however, the GROUP BY / COUNT and JOIN queries will always need to look for ALL matching sales per customer, and the IN query will still usually need to build the list of s.sale_customer_id values from the Sales table before looking for a match on c.customer_id. I would not at all be surprised if some query optimiser engines are smart enough to spot the IN pattern and decide to do the “short-circuit” thing there for each c.customer_id, but again personally I would reach for the safe shortcut behaviour of EXISTS. As a bonus you also get the expressed clarity of intent with that SQL operator.
Can a correlated subquery refer to more than one column from the parent query?
Yes it can. In fact you can reference columns from multiple tables in both the parent query and the subquery if you like. Think of the correlated conditions (e.g. WHERE sub.col1 = parent1.col1 AND sub.col2 = parent2.col1) as bringing in the entire row from the parent query table(s).
Once again, remember to index the columns in the subquery tables which you are correlating with the parent query.
Key takeaways
- The EXISTS and correlated subquery combo is a powerful technique for quickly finding the existence of matching data, as opposed to details such as counts.
- EXISTS returns TRUE as soon as one matching row is found in the associated subquery, and immediately stops the search for others.
- This “short circuit” behaviour can lead to significantly faster queries, for large datasets and the right use-case.
- Correlated subqueries reference columns from the parent query.
- A mental model for thinking about correlated subqueries is a parameterised subroutine, where the input values are streamed in from the parent query.
- Good indexing unlocks the EXISTS and correlated subquery combo and makes it significantly faster!
Conclusion
For the instances where you simply want to identify the existence of a row which satisfies some criteria, and you don’t care about counts or aggregates, the EXISTS/correlated subquery combo can be just the (often highly efficient) ticket. Perhaps you have some SQL code fragments which include COUNT( * ) > 0 or LEFT OUTER JOIN / ISNULL which run faster after some refactoring into an EXISTS or NOT EXISTS structure. Give it a try! Keep in the back of your mind that “parameterised subroutine call” functionality, and this EXISTS/correlated subquery structure could become a highly useful tool in your SQL toolkit.
The full demo SQL code for this blog post is available below.
/*
DISCLAIMER:
The scripts provided in this blog post are for educational and demonstration purposes only.
They are provided "as-is" without warranty of any kind, either expressed or implied,
including but not limited to the implied warranties of merchantability or fitness for a
particular purpose. Use these scripts at your own risk.
The author is not responsible for any data loss, corruption, or system issues that may
arise from running these scripts in any environment. Please ensure to test these scripts
thoroughly in a non-production environment before using them in production systems.
The scripts are designed for SQL Server and may require adjustments for other database systems.
Please review and modify as needed to suit your specific use case.
*/
/*
https://shanedriscoll.com/sql/exists-and-correlated-subqueries-combo/
*/
DROP TABLE IF EXISTS
dbo.Sales;
DROP TABLE IF EXISTS
dbo.Customers;
DROP TABLE IF EXISTS
dbo.Books;
/* Customers table */
CREATE TABLE
dbo.Customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100)
);
/* Books table */
CREATE TABLE dbo.Books (
book_id INT PRIMARY KEY
,book_name VARCHAR(100)
,book_category VARCHAR(100)
,book_price DECIMAL(10, 2)
);
/* Sales table*/
CREATE TABLE dbo.Sales (
sale_id INT PRIMARY KEY
,sale_date DATE
,sale_customer_id INT
,sale_book_id INT FOREIGN KEY (sale_customer_id) REFERENCES dbo.Customers(customer_id)
,FOREIGN KEY (sale_book_id) REFERENCES dbo.Books(book_id)
);
/* Insert Customers */
INSERT INTO
Customers (customer_id, customer_name)
VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie'),
(4, 'Danielle'),
(5, 'Ed');
/* Insert Books */
INSERT INTO dbo.Books (
book_id
,book_name
,book_category
,book_price
)
VALUES
(1, 'The Art of French Cooking', 'Cooking', 29.99),
(2, 'BBQ Mastery: Grilling Like a Pro', 'Cooking', 24.50),
(3, 'Whispers of the Heart', 'Romance', 15.99),
(4, 'The Duke''s Secret', 'Romance', 18.75),
(5, 'Galactic Wars: The Rise of Andromeda', 'SciFi', 22.99),
(6, 'Quantum Dreams', 'SciFi', 19.99),
(7, 'Time Travelers of Mars', 'SciFi', 21.50),
(8, 'The Fall of Rome', 'History', 27.99),
(9, 'World War Chronicles', 'History', 30.00),
(10, 'The Age of Pharaohs', 'History', 25.99);
/* Insert Sales */
INSERT INTO dbo.Sales (
sale_id
,sale_date
,sale_customer_id
,sale_book_id
)
VALUES
(1, '2024-12-02', 1, 5),
(2, '2024-04-19', 2, 3),
(3, '2024-04-15', 4, 5),
(4, '2024-03-20', 5, 8),
(5, '2024-11-27', 1, 1),
(6, '2024-09-16', 5, 6),
(7, '2024-01-03', 1, 9),
(8, '2024-07-04', 2, 9),
(9, '2024-10-03', 2, 8),
(10, '2024-03-19', 5, 9),
(11, '2024-03-19', 1, 6);
/* Which customers have made a purchase? */
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE EXISTS (
SELECT 1
FROM dbo.Sales AS s
WHERE s.sale_customer_id = c.customer_id
);
/* Which customers have not made any purchases? */
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE NOT EXISTS (
SELECT 1
FROM dbo.Sales AS S
WHERE s.sale_customer_id = c.customer_id
);
/* Which books have not had any sales? */
SELECT b.book_name
FROM dbo.Books AS b
WHERE NOT EXISTS (
SELECT 1
FROM dbo.Sales AS S
WHERE s.sale_book_id = b.book_id
);
/* Who bought the book “The Fall of Rome”, and has never bought a romance book? */
SELECT c.customer_name
FROM dbo.Customers AS c
WHERE EXISTS (
SELECT 1
FROM dbo.Sales AS s_for
INNER JOIN dbo.Books AS b ON s_for.sale_book_id = b.book_id
WHERE s_for.sale_customer_id = c.customer_id
AND b.book_name = 'The Fall of Rome'
)
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales AS s_romance
INNER JOIN dbo.Books AS b ON s_romance.sale_book_id = b.book_id
WHERE s_romance.sale_customer_id = c.customer_id
AND b.book_category = 'Romance'
);
/* Who has only ever bought SciFi books worth more than £22? */
SELECT c.customer_name
FROM dbo.Customers c
WHERE
/* Make sure the customer has purchased at least 1 book */
EXISTS (
SELECT 1
FROM dbo.Sales s
WHERE s.sale_customer_id = c.customer_id
)
/* Make sure the customer has NOT purchased any non-SciFi books */
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales s_non_scifi
INNER JOIN dbo.Books b_non_scifi ON s_non_scifi.sale_book_id = b_non_scifi.book_id
WHERE s_non_scifi.sale_customer_id = c.customer_id
AND b_non_scifi.book_category != 'SciFi'
)
/* Make sure the customer has NOT purchased any SciFi books which cost < £22 */
AND NOT EXISTS (
SELECT 1
FROM dbo.Sales s_cheap_scifi
INNER JOIN dbo.Books b_cheap_scifi ON s_cheap_scifi.sale_book_id = b_cheap_scifi.book_id
WHERE s_cheap_scifi.sale_customer_id = c.customer_id
AND b_cheap_scifi.book_category = 'SciFi'
AND b_cheap_scifi.book_price <= 22
);
/* Who purchased a history book which a different customer has purchased? */
SELECT c.customer_name
FROM dbo.Customers c
WHERE EXISTS (
/* Has this customer purchased a history book? */
SELECT 1
FROM dbo.Sales s_hist1
INNER JOIN dbo.Books b_hist1 ON s_hist1.sale_book_id = b_hist1.book_id
WHERE s_hist1.sale_customer_id = c.customer_id
AND b_hist1.book_category = 'History'
AND EXISTS (
/* Has a different customer to the one we are looking at purchased the same book? */
SELECT 1
FROM dbo.Sales s_hist2
WHERE s_hist2.sale_book_id = s_hist1.sale_book_id
AND s_hist2.sale_customer_id != s_hist1.sale_customer_id
)
);
/* Cleanup */
DROP TABLE IF EXISTS
dbo.Sales;
DROP TABLE IF EXISTS
dbo.Customers;
DROP TABLE IF EXISTS
dbo.Books;